IAM Handwriting Database
Overview
The IAM Handwriting Database contains forms of handwritten English text which can be used to train and test handwritten text recognizers and to perform writer identification and verification experiments.
The database was first published in [1] at the ICDAR 1999. Using this database an HMM based recognition system for handwritten sentences was developed and published in [2] at the ICPR 2000. The segmentation scheme used in the second version of the database is documented in [3] and has been published in the ICPR 2002. The IAM-database as of October 2002 is described in [4]. We use the database extensively in our own research, see publications for further details.
The database contains forms of unconstrained handwritten text, which were scanned at a resolution of 300dpi and saved as PNG images with 256 gray levels. The figure below provides samples of a complete form, a text line and some extracted words.
 |
|
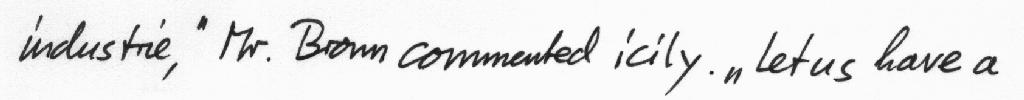
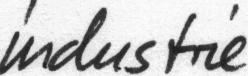
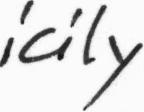
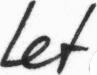
All forms and also all extracted text lines, words and sentences are available for download as PNG files, with corresponding XML meta-information included into the image files. All texts in the IAM database are built using sentences provided by the LOB Corpus [5].
Characteristics
The IAM Handwriting Database 3.0 is structured as follows:
- 657 writers contributed samples of their handwriting
- 1'539 pages of scanned text
- 5'685 isolated and labeled sentences
- 13'353 isolated and labeled text lines
- 115'320 isolated and labeled words
The words have been extracted from pages of scanned text using an automatic segmentation scheme and were verified manually. The segmentation scheme has been developed at our institute [3].
All form, line and word images are provided as PNG files and the corresponding form label files, including segmentation information and variety of estimated parameters (from the preprocessing steps described in [2]), are included in the image files as meta-information in XML format which is described in XML file and XML file format (DTD).
Changes in Version 3.0
Apart from greatly extending the database, the word and characters have been extracted and segmented using a different method than the one used in previous versions. In theory this change can lead to different results. In practice it should not be of any importance.
Download
Before you can download the IAM Handwriting DB 3.0 we ask you to register so we are aware of who is using our data. Once you have registered you access the IAM Handwriting DB 3.0.
Tasks
A task defines an experiment with well defined training, test, and validation sets. The idea of a task it to allow researchers to compare the results of their experiments.
We have defined the following tasks:
-
Large Writer Independent Text Line Recognition Task
This task consists of a total number of 9'862 text lines. It provides one training, one testing, and two validation sets. The text lines of all data sets are mutually exclusive, thus each writer has contributed to one set only.
Set Name Number of Text Lines Number of Writers Train 6'161 283 Validation 1 900 46 Validation 2 940 43 Test 1'861 128 Total 9'862 500 The IDs of the different sets can be downloaded here.
Terms of Use and Citation Request
This database may be used for non-commercial research purpose only. If you publish material based on this database, we request you to include a reference to paper [4].
Contact
If you have any questions or suggestions, please use the contact form.
References
[1] U. Marti and H. Bunke. A full English sentence database for off-line handwriting recognition. In Proc. of the 5th Int. Conf. on Document Analysis and Recognition, pages 705 - 708, 1999.
[2] U. Marti and H. Bunke. Handwritten Sentence Recognition. In Proc. of the 15th Int. Conf. on Pattern Recognition, Volume 3, pages 467 - 470, 2000.
[3] M. Zimmermann and H. Bunke. Automatic Segmentation of the IAM Off-line Database for Handwritten English Text. In Proc. of the 16th Int. Conf. on Pattern Recognition, Volume 4, pages 35 - 39, 2000.
[4] U. Marti and H. Bunke. The IAM-database: An English Sentence Database for Off-line Handwriting Recognition. Int. Journal on Document Analysis and Recognition, Volume 5, pages 39 - 46, 2002.
[5] S. Johansson, G.N. Leech and H. Goodluck. Manual of Information to accompany the Lancaster-Oslo/Bergen Corpus of British English, for use with digital Computers. Department of English, University of Oslo, Norway, 1978.